51
Actually Useful AI
2720 readers
1 users here now
Welcome! 🤖
Our community focuses on programming-oriented, hype-free discussion of Artificial Intelligence (AI) topics. We aim to curate content that truly contributes to the understanding and practical application of AI, making it, as the name suggests, "actually useful" for developers and enthusiasts alike.
Be an active member! 🔔
We highly value participation in our community. Whether it's asking questions, sharing insights, or sparking new discussions, your engagement helps us all grow.
What can I post? 📝
In general, anything related to AI is acceptable. However, we encourage you to strive for high-quality content.
What is not allowed? 🚫
- 🔊 Sensationalism: "How I made $1000 in 30 minutes using ChatGPT - the answer will surprise you!"
- ♻️ Recycled Content: "Ultimate ChatGPT Prompting Guide" that is the 10,000th variation on "As a (role), explain (thing) in (style)"
- 🚮 Blogspam: Anything the mods consider crypto/AI bro success porn sigma grindset blogspam
General Rules 📜
Members are expected to engage in on-topic discussions, and exhibit mature, respectful behavior. Those who fail to uphold these standards may find their posts or comments removed, with repeat offenders potentially facing a permanent ban.
While we appreciate focus, a little humor and off-topic banter, when tasteful and relevant, can also add flavor to our discussions.
Related Communities 🌐
General
- !Artificial@kbin.social
- !artificial_intel@lemmy.ml
- !singularity@lemmy.fmhy.ml
- !ai@kbin.social
- !ArtificialIntelligence@kbin.social
- !aihorde@lemmy.dbzer0.com
Chat
Image
Open Source
Please message @sisyphean@programming.dev if you would like us to add a community to this list.
Icon base by Lord Berandas under CC BY 3.0 with modifications to add a gradient
founded 2 years ago
MODERATORS
53
54
55
56
9
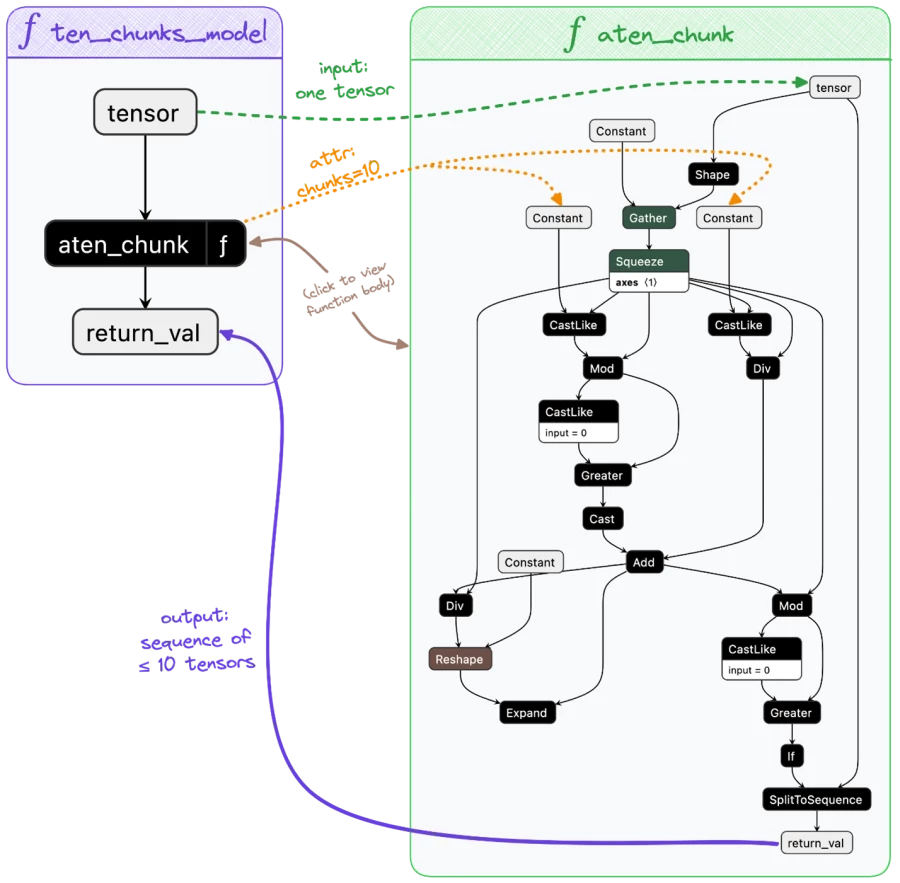
Introducing ONNX Script: Authoring ONNX with the ease of Python - Microsoft Open Source Blog
(cloudblogs.microsoft.com)
57
58
59
60
61
62
63
64
65

66

67
68
69
70
cross-posted from: https://lemmy.intai.tech/post/133548
https://arxiv.org/pdf/1706.03762.pdf
Attention Is All You Need
By Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin
Word count: 4221
Estimated read time: 17 minutes
Links:
Summary: This paper proposes a new neural network architecture called the Transformer that is based solely on attention mechanisms, without using sequence aligned RNNs or convolutions. The Transformer achieves state-of-the-art results in machine translation while being more parallelizable and requiring significantly less time to train. Key contributions:
Proposes multi-head self-attention as a replacement for recurrence and convolutions in encoder-decoder architectures. Self-attention connects all positions with a constant number of sequentially executed operations, whereas recurrent layers require O(n) sequential operations.
Introduces scaled dot-product attention, which performs better than additive attention for large values of attention dimension. Applies attention scaling to improve training.
Employs positional encodings instead of recurrence to enable the model to make use of sequence order. Shows that learned positional embeddings can replace sinusoids with negligible loss in quality.
Achieves state-of-the-art BLEU scores on WMT 2014 English-to-German and English-to-French translation at a fraction of the training cost of previous models. Outperforms all previously published models on English constituency parsing with limited training data.
The Transformer's reliance on attention and positional encodings rather than recurrence make it very promising for parallelization and scaling to longer sequences. The results demonstrate the potential of attention-based models to supplant RNNs and CNNs in sequence transduction tasks.
Evaluation: The Transformer architecture presents several advantages for using large language models and generative adversarial networks:
The Transformer is highly parallelizable since it does away with sequence-aligned RNNs. This makes it very suitable for scaling up with more parameters and data.
The multi-head self-attention provides a way to jointly attend to information from different representation subspaces at different positions, allowing modeling of dependencies regardless of distance. This is useful for long-range dependencies in large contexts.
Positional encodings allow the model to make use of sequence order without recurrence. This can enable generating coherent, ordered outputs in GANs and large LMs.
The Transformer achieves excellent results with limited training data, suggesting its representations transfer well. This is promising for few-shot learning and fine-tuning large LMs.
The paper provides useful analysis into the roles different attention heads learn, which can inform work on interpretable attention-based representations.
Overall, the Transformer architecture seems very promising as a foundation for large scale language modeling and GAN training. The representations it learns appear powerful yet transparent. The results on parsing suggest it can capture linguistic phenomena well. The parallelizability enables scaling. Much follow-on work has already adapted and refined the Transformer, making it very relevant today.

71
72
73
cross-posted from: https://lemmy.intai.tech/post/124795
Large Language Models as Tool Makers Authors: Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, Denny Zhou
Word count: 4579 words
Estimated read time: 12 minutes
Source code: https://github.com/ctlllll/LLM-ToolMaker ↗
Summary:
This paper proposes a framework called LLMs As Tool Makers (LATM) that enables large language models (LLMs) to create and utilize their own tools for solving complex reasoning tasks. The key idea is to separate the process into two stages - tool making and tool using. In the tool making stage, a powerful yet expensive LLM acts as the "tool maker" to generate reusable Python functions for solving demonstrations of a task. In the tool using stage, a lightweight and cost-effective LLM acts as the "tool user" to call these tools to solve new instances of the task.
Experiments on tasks like logical deduction, tracking shuffled objects, Dyck language parsing, etc show that with tools made by GPT-4, GPT-3.5 Turbo as the tool user can match or exceed the performance of GPT-4 at lower cost. The authors also introduce a "dispatcher" LLM to handle streaming tasks by identifying when to reuse existing tools or request new ones.
Overall, this work demonstrates a promising approach to enabling LLMs to create their own tools, reducing reliance on human-crafted tools. The division of labor also allows using smaller models for most of the inferences, improving cost-efficiency. This technique could significantly expand the capabilities of LLMs in a scalable manner.
The proposed LATM framework demonstrates an interesting and promising approach to improving the reasoning and problem-solving capabilities of large language models in a cost-effective manner. Here are some thoughts on its applicability:
The ability for LLMs to create their own tools could be very useful for building practical applications. For any recurring task, the model could generate a reusable tool instead of solving from scratch each time. This could make applications more efficient and scalable.
The staged approach allows combining different sized models optimally - a powerful model makes tools, while lightweight models use the tools. This cost-effectiveness is attractive for real-world applications with budget constraints.
The tools being in Python allows them to integrate into application codebases easily. The dispatcher model also provides flexibility to handle new tasks.
The method's applicability does seem more geared towards logical reasoning, procedural and algorithmic tasks right now. Further research may be needed to extend it to other domains.
There are still open challenges around rigorously testing and validating the quality and safety of automatically generated tools. Methods to provide human oversight would be important.
Overall, the LATM paradigm does appear promising for augmenting LLMs and enabling them to participate more actively in their own learning and tooling. With further research to broaden its scope, it could become a general framework for efficiently enhancing LLM capabilities.
So in summary, LATM seems quite promising as a technique for unlocking more of the potential of LLMs for practical applications requiring complex reasoning in a scalable and cost-efficient manner. More research is still needed, but the principles demonstrated align well with enabling wider usage of LLMs and GANs in applications.

74
75
36