For part one and likely part 2 you don't need to do all 499500 comparisons, you could split the grid into boxes and only search adjacent ones. E.g. z / 10 = which decile and look at z, z-1, z+1 (and the same for x and y). Less work for the processor, more work for you, and of course, sqrt (which you can also probably skip) is so efficient on modern chips that the overhead of this eats a chunk of the benefits (depending on how low-level your language is).
Deebster
joined 2 years ago
Rust
Part 1 took a decent while, partly life getting in the way, partly as I was struggling with some Rust things like floats not being sortable without mucking around, plus some weird bugs trying to get collect to do everything that I eventually just rewrote to avoid.
I found the noisy_float crate which let me wrap f64 as a "real" r64 which meant no NaN which meant Ord which meant sort_by_cached_key() and the rest worked.
I'd planned how to partition the closest neighbour search, but the whole thing runs in 24ms so I didn't bother.
other types
type Id = usize;
type Connection = (Id, Id);
type Circuit = HashSet<Id>;
#[derive(PartialEq)]
struct Point {
x: usize,
y: usize,
z: usize,
}
impl FromStr for Point {
type Err = Report;
fn from_str(s: &str) -> Result<Self> {
let mut parts = s.split(',');
Ok(Point {
x: parts.next().ok_or_eyre("missing x")?.parse()?,
y: parts.next().ok_or_eyre("missing y")?.parse()?,
z: parts.next().ok_or_eyre("missing z")?.parse()?,
})
}
}
impl Point {
fn distance(&self, other: &Point) -> R64 {
let dist = ((
self.x.abs_diff(other.x).pow(2) +
self.y.abs_diff(other.y).pow(2) +
self.z.abs_diff(other.z).pow(2)) as f64)
.sqrt();
r64(dist)
}
}
struct Boxes(Vec<Point>);
impl Boxes {
fn closest(&self) -> Vec<Connection> {
let mut closest = (0..self.0.len())
.flat_map(|a| ((a + 1)..self.0.len()).map(move |b| (a, b)))
.collect::<Vec<_>>();
closest.sort_by_cached_key(|&(a, b)| self.0[a].distance(&self.0[b]));
closest
}
fn connect_all(&self, p1_threshold: usize) -> Result<(usize, usize)> {
let mut circuits: Vec<Circuit> = (0..self.0.len())
.map(|id| HashSet::from_iter(iter::once(id)))
.collect();
let mut closest = self.closest().into_iter();
let mut p1 = 0;
let mut n = 0;
loop {
n += 1;
let (a, b) = closest.next().ok_or_eyre("All connected already")?;
let a_circ = circuits.iter().position(|c| c.contains(&a));
let b_circ = circuits.iter().position(|c| c.contains(&b));
match (a_circ, b_circ) {
(None, None) => {
circuits.push(vec![a, b].into_iter().collect());
}
(None, Some(idx)) => {
circuits[idx].insert(a);
}
(Some(idx), None) => {
circuits[idx].insert(b);
}
(Some(a_idx), Some(b_idx)) if a_idx != b_idx => {
let keep_idx = a_idx.min(b_idx);
let rem_idx = a_idx.max(b_idx);
let drained = circuits.swap_remove(rem_idx);
// this position is still valid since we removed the later set
circuits[keep_idx].extend(drained);
}
_ => { /* already connected to same circuit */ }
};
if n == p1_threshold {
circuits.sort_by_key(|set| set.len());
circuits.reverse();
p1 = circuits.iter().take(3).map(|set| set.len()).product();
}
if circuits.len() == 1 {
let p2 = self.0[a].x * self.0[b].x;
return Ok((p1, p2));
}
}
}
}
I normally use the "most appropriate" size, but this year I'm just using usize everywhere and it's a lot more fun. So far I haven't found any problem where it ran too slow and the problem was in my implementation and not my algorithm choice.
Ah, it took me looking at your updated Codeberg version to understand this - you looked at part two in the opposite way than I did but it comes out the same in the end (and yours is much more efficient).
QIR (Quantum Intermediate Representation)
Nah, just kidding - I used Rust. The only tricky part seemed to be finding time on a Sunday to get it coded!
Part 1 I swept down with a bool array for beams and part 2 I swept up with a score array and summed when it split (joined).
struct Teleporter(String);
impl Teleporter {
fn new(s: String) -> Self {
Self(s)
}
fn start_pos(line: &str) -> Result<usize> {
line.find('S').ok_or_eyre("Start not found")
}
fn splits(&self) -> Result<usize> {
let mut input = self.0.lines();
let start_line = input.next().ok_or_eyre("No start line")?;
let start = Self::start_pos(start_line)?;
let mut beams = vec![false; start_line.len()];
beams[start] = true;
let mut splits = 0;
for line in input {
for (i, ch) in line.bytes().enumerate() {
if beams[i] && ch == b'^' {
splits += 1;
beams[i] = false;
beams[i - 1] = true;
beams[i + 1] = true;
}
}
}
Ok(splits)
}
fn timelines(&self) -> Result<usize> {
let mut input = self.0.lines();
let start_line = input.next().ok_or_eyre("No start line")?;
let start = Self::start_pos(start_line)?;
let mut num_paths = vec![1; start_line.len()];
for line in input.rev() {
for (i, c) in line.bytes().enumerate() {
if c == b'^' || c == b'S' {
num_paths[i] = num_paths[i - 1] + num_paths[i + 1];
}
}
}
Ok(num_paths[start])
}
}

Why not use .iter().sum() and .iter().product()?
nushell
I was afk when the puzzle went up so I had another go at doing it on my phone in Turmux with my shell's scripting language. It's quite nice how your shell is also a REPL so you can build up the answer in pieces, although I wrote a file for the second part.
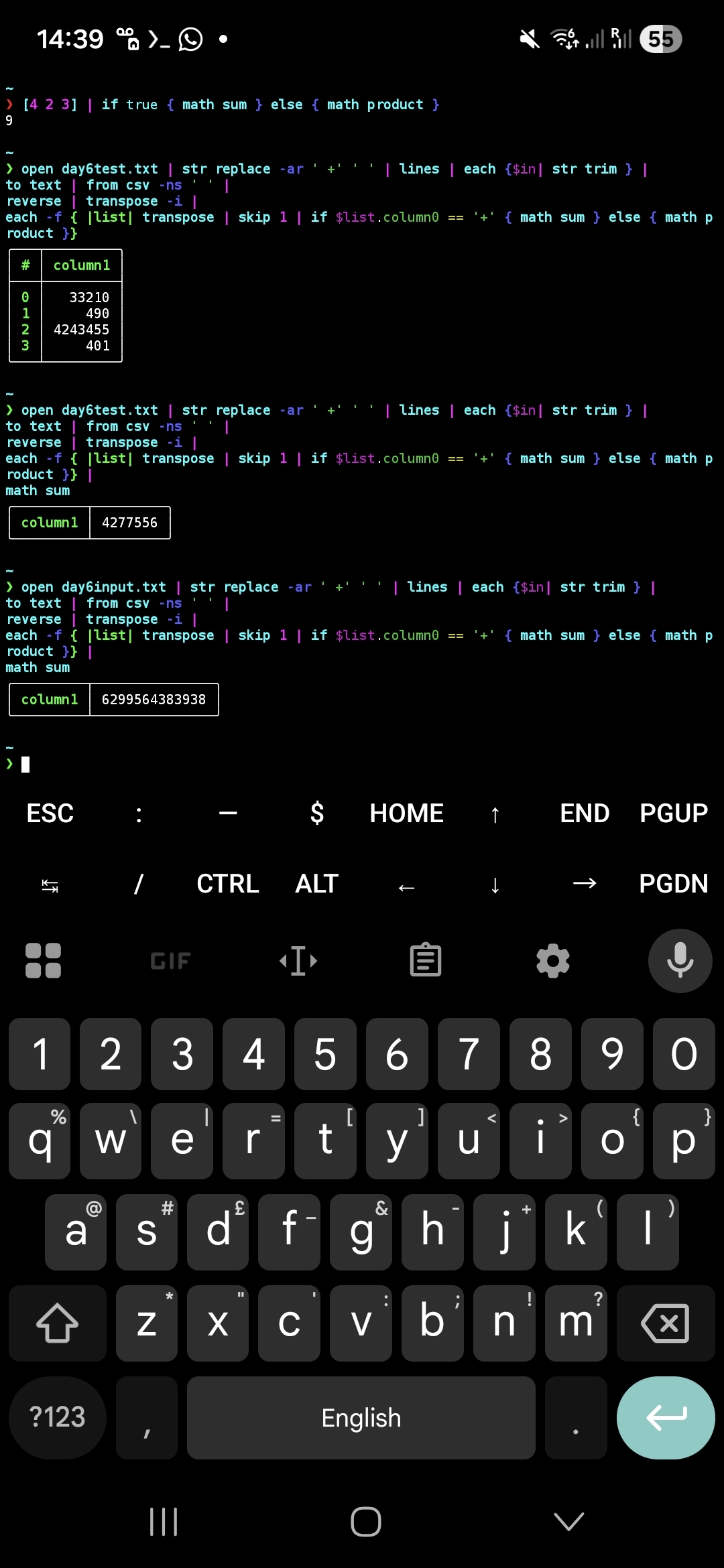
open input.txt | str replace --all --regex ' +' ' ' |
lines | each { $in | str trim } | to text |
from csv --noheaders --separator ' ' |
reverse | transpose --ignore-titles |
each {
|list| transpose | skip 1 | if $list.column0 == '+' { math sum } else { math product }
} |
math sum
Part 2
let input = open input.txt | lines | each { $in | split chars }
let last_row = ($input | length) - 1
let last_col = ($input | first | length) - 1
mut op = ' '
mut numbers = []
mut grand_tot = 0
for x in $last_col..0 {
if $op == '=' {
$op = ' '
continue
}
let n = 0..($last_row - 1) | each { |y| $input | get $y | get $x } | str join | into int
$numbers = ($numbers | append $n)
$op = $input | get $last_row | get $x
if $op != ' ' {
$grand_tot += $numbers | if $op == '+' { math sum } else { math product }
$numbers = []
$op = '='
}
}
$grand_tot
Rust
I didn't look at the input at first so tried a naive version with sets, but it was too slow even for part one. I got smarter and wrote a version with less code that runs in under half a millisecond.
type Id = usize;
struct Ingredients {
fresh: Vec<RangeInclusive<Id>>,
available: HashSet<Id>,
}
impl Ingredients {
fn is_fresh(&self, id: Id) -> bool {
self.fresh.iter().any(|range| range.contains(&id))
}
fn num_fresh_available(&self) -> usize {
self.available
.iter()
.filter(|&&id| self.is_fresh(id))
.count()
}
fn num_fresh_all(&self) -> usize {
self.fresh
.iter()
.map(|range| 1 + range.end() - range.start())
.sum()
}
}
fn merge_ranges(mut ranges: Vec<RangeInclusive<Id>>) -> Vec<RangeInclusive<Id>> {
if ranges.is_empty() {
return ranges;
}
ranges.sort_by_key(|range| *range.start());
let mut merged = Vec::new();
let mut start = ranges[0].start();
let mut end = ranges[0].end();
for range in ranges.iter().skip(1) {
if range.start() > end {
merged.push(RangeInclusive::new(*start, *end));
start = range.start();
end = range.end();
}
if range.end() > end {
end = range.end();
}
}
merged.push(RangeInclusive::new(*start, *end));
merged
}
impl FromStr for Ingredients {
type Err = Report;
fn from_str(s: &str) -> Result<Self, Self::Err> {
let Some((fresh_str, avail_str)) = s.split_once("\n\n") else {
bail!("missing divider");
};
let fresh = fresh_str
.lines()
.map(|l| -> Result<RangeInclusive<_>, Self::Err> {
let (start, end) = l.split_once('-').ok_or_eyre("bad range")?;
let start: Id = start.parse()?;
let end: Id = end.parse()?;
Ok(start..=end)
})
.collect::<Result<_, _>>()?;
let available = avail_str
.lines()
.map(|l| l.parse())
.collect::<Result<_, _>>()?;
Ok(Ingredients {
fresh: merge_ranges(fresh),
available,
})
}
}
::: spoiler Full code
use std::{collections::HashSet, fs, ops::RangeInclusive, str::FromStr};
use color_eyre::eyre::{OptionExt, Report, Result, bail};
#[derive(Debug, PartialEq, Eq)]
struct Ingredients {
fresh: Vec<RangeInclusive<Id>>,
available: HashSet<Id>,
}
type Id = usize;
impl Ingredients {
fn is_fresh(&self, id: Id) -> bool {
self.fresh.iter().any(|range| range.contains(&id))
}
fn num_fresh_available(&self) -> usize {
self.available
.iter()
.filter(|&&id| self.is_fresh(id))
.count()
}
fn num_fresh_all(&self) -> usize {
self.fresh
.iter()
.map(|range| 1 + range.end() - range.start())
.sum()
}
}
fn merge_ranges(mut ranges: Vec<RangeInclusive<Id>>) -> Vec<RangeInclusive<Id>> {
if ranges.is_empty() {
return ranges;
}
ranges.sort_by_key(|range| *range.start());
let mut merged = Vec::new();
let mut start = ranges[0].start();
let mut end = ranges[0].end();
for range in ranges.iter().skip(1) {
if range.start() > end {
merged.push(RangeInclusive::new(*start, *end));
start = range.start();
end = range.end();
}
if range.end() > end {
end = range.end();
}
}
merged.push(RangeInclusive::new(*start, *end));
merged
}
impl FromStr for Ingredients {
type Err = Report;
fn from_str(s: &str) -> Result<Self, Self::Err> {
let Some((fresh_str, avail_str)) = s.split_once("\n\n") else {
bail!("missing divider");
};
let fresh = fresh_str
.lines()
.map(|l| -> Result<RangeInclusive<_>, Self::Err> {
let (start, end) = l.split_once('-').ok_or_eyre("bad range")?;
let start: Id = start.parse()?;
let end: Id = end.parse()?;
Ok(start..=end)
})
.collect::<Result<_, _>>()?;
let available = avail_str
.lines()
.map(|l| l.parse())
.collect::<Result<_, _>>()?;
Ok(Ingredients {
fresh: merge_ranges(fresh),
available,
})
}
}
fn part1(filepath: &str) -> Result<usize> {
let input = fs::read_to_string(filepath)?;
let ingrd = Ingredients::from_str(&input).unwrap();
Ok(ingrd.num_fresh_available())
}
fn part2(filepath: &str) -> Result<usize> {
let input = fs::read_to_string(filepath)?;
let ingrd = Ingredients::from_str(&input).unwrap();
Ok(ingrd.num_fresh_all())
}
fn main() -> Result<()> {
color_eyre::install()?;
println!("Part 1: {}", part1("d05/input.txt")?);
println!("Part 2: {}", part2("d05/input.txt")?);
Ok(())
}
Ha, I've got that article half-read in a tab somewhere. Same problem here though - they're not in the standard library for anything I plan to use for AoC.
Bacon is a Rust code checker designed for minimal interaction, allowing users to run it alongside their editor to receive real-time notifications about warnings, errors, or test failures (I like having it show clippy's hints).
It prioritizes displaying errors before warnings, making it easier to identify critical issues without excessive scrolling.
Screenshot (from an old version I think):

v3 adds support for cargo-nextest, plus some QoL improvements.
Hover text:
Our nucleic acid recovery techinques found a great deal of homo sapiens DNA incorporated into the fossils, particularly the ones containing high levels of resin, leading to the theory that these dinosaurs preyed on the once-dominant primates.
Transcript:
[Three squid-like aliens in a classroom; one alien stands in front of a board covered with minute text and a drawing of a T-Rex skeleton. Two aliens sit on stools watching the teacher alien. The teacher alien on the left is on a raised platform and points at the board with one tentacle.]
Left alien: Species such as triceratops and tyrannosaurus became more rare after the Cretaceous, but they survived to flourish in the late Cenozoic, 66 million years later.
Left alien: Many complete skeletons have been discovered from this era.
[Caption below the panel:]
It's going to be really funny when our museums get buried in sediment.

That is surprising about Firefox - you'd have thought something that literally just runs JavaScript would be able to beat Firefox with all the UI, sandboxing, etc. 30% is a huge margin.