Starting at midnight Thursday night through midnight Friday night, we will be joining with people across the country and beyond to demonstrate our collective outrage over the hostile takeover of our government by unelected billionaires and by those who put profits before people. For one day, this Friday, we pledge not to buy anything from any major online or in-person retailers, and we pledge to refrain from using credit cards. We recommend staying away from Facebook, Instagram, and “X.”
This action began as a protest against those corporations who abandoned diversity, equity, and inclusion programs to placate a white supremacist administration. Those corporations include Target, Citi Bank, Google, and Disney. It quickly expanded into a “Buy Nothing Day,” with particular recognition of the role of finance capital. The concept of Economic Blackout 2/28 has quickly spread on social media, propelled by activists, faith communities, students, and rank-and-file workers everywhere. The movement goes beyond our borders. In Canada, consumers will target USA-based companies to protest Trump’s tariffs, and Mexicans will participate in the Latino Freeze Movement to protest US anti-immigrant and anti-DEI policies.
Please participate in this action! It is a simple act that we all can accomplish and that can quickly add up to a collective impact.
Sign our pledge today!
In resistance,
National Board, CPUSA

{kind=link}
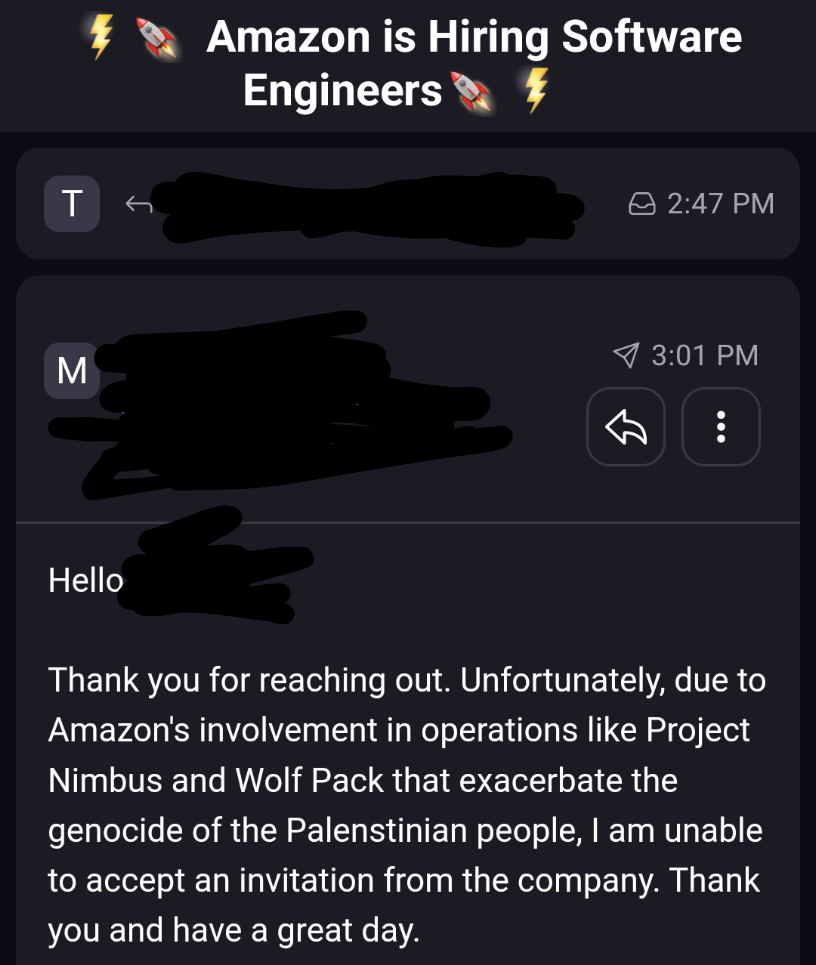
I wish we had 5 minute headways haha.