I should hope that they're right. We should return what was stolen.
danielquinn
joined 2 years ago
You do not need to pave green space to build homes. There's plenty of paved, ugly, low-density areas in desperate need of upgrades. The problem is the British public's obsession with that idea that everyone needs their own patch of grass and two cars.
As someone else said here, programmers are not a monolith. However, I've seen it multiple times on the job and in social media where programmers are using these tools to write code voluntarily. The code produced is often garbage, and I have to reject it at review time, but there are a lot of programmers using these things willingly.
Why would they do that? The current system ensures that at least one of them will always be in charge, and they effectively have the same politics.
They already do.
Please don't give this any credit. Nonsense like this is already being used to filter web form submissions for things like job applications.
Source: I applied for a role at a medium-sized company a couple weeks ago and was auto-rejected because my cover letter appeared to be AI-generated. I clicked "back", removed an em-dash, and the form was accepted.
How can anyone hate someone so much, when she never did anything to them?
Imagine that your life is terrible. You're poor, desperate, maybe ill too. You live with your parents who are also poor and desperate, and the lot of you self medicate with copious amounts of alcohol.
You're miserable, and not terribly bright. Then one day, your primary media sources and even the governing political party starts parroting the same lie that the reason your life if shit is because trans people and immigrants exist. No one with a similarly large platform is telling you the truth.
Now consider how many millions of purple have been abandoned by the state in this country. How many poor and desperate people we've made in the last 10 years and the incentive the owning class has in laying the blame for that at the feet of anyone but themselves.
Hate is learnt, and the teachers are holding all the money & power.
It's pretty standard.
Honestly, I'd favour dropping any incentives for EVs, so long as Canada were to then redirect its efforts into transit and active transport. You just can't replace every combustion car on the road with an EV, but you can narrow roads, reduce lanes, and add trains, trams, and cycle paths.
Hooooly shit, that man is a sociopath. It's no wonder we're barrelling into 5°C with people like him driving the world's economy.
He's done the classic trader thing:
- Classify everything based on its financial value
- Ignore the real-world implications of things that don't fit his models
- Take it as a given that markets will always behave the same way regardless of point 2.
{kind=link}
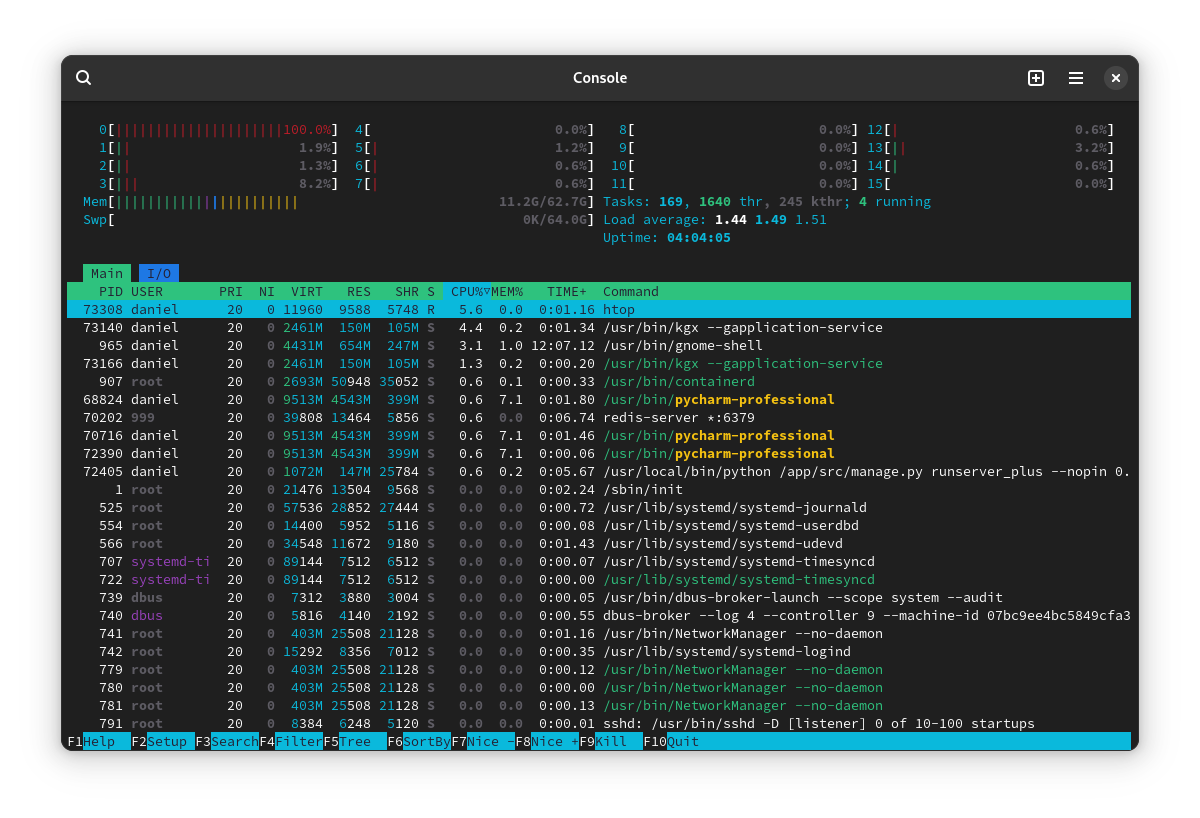
From time to time, often after I've restored from sleep or finished playing a Steam game, one of my CPU cores is pinned at 100% with no indication of what might be doing it. Running htop, btop, or GNOME system monitor all show the same thing: CPU0 at 100% while the rest are doing near-nothing, and no process in particular seems to be using those resources.
If I restart, it's back to normal, and sometimes I can play a game in Steam or let the computer go to sleep and it doesn't do this, but it happens often enough that's annoying/confusing so I'd like to know if there's a way to either (a) diagnose which processes are using which CPU cores, or (b) somehow "reset" the checking of these values to make sure that something's not just being misreported.
This is a desktop system running Arch & GNOME.
view more: next ›
Yes. It would.