this post was submitted on 06 Oct 2025
861 points (99.5% liked)
Microblog Memes
9458 readers
3059 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
- Posters are encouraged to link to the toot or tweet etc in the description of posts.
Related communities:
founded 2 years ago
MODERATORS
{kind=link}
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
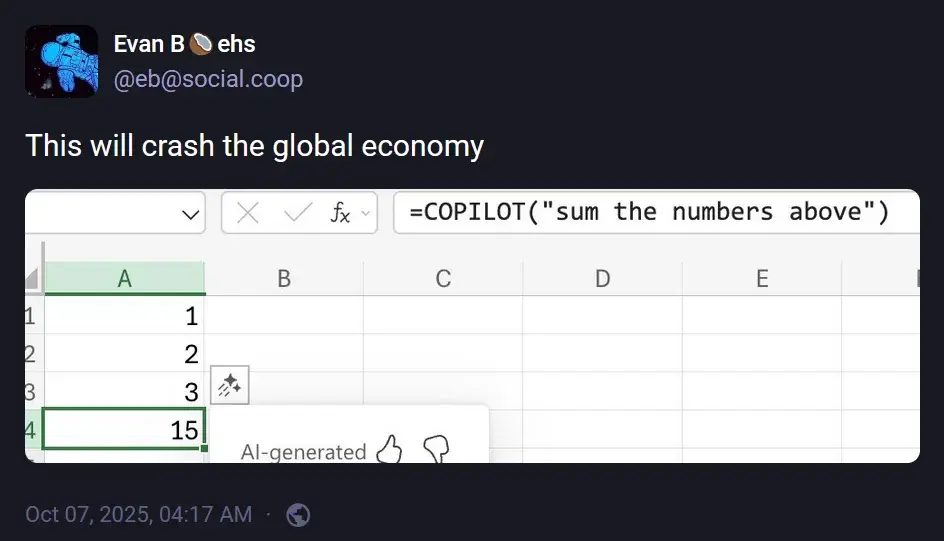
Because there is no "it" that "calls" or "identify" even less the "nature of the question".
This requires intelligence, not probability on the most likely next token.
You can do maths with words and you can write poem with numbers, either requires to actually understand, that's the linchpin, rather than parse and provide an answer based on what has been written so far.
Sure the model might string together tokens that sound very "appropriate" to the question, in the sense that it fits within the right vocabulary, and if its dataset the occurrence was just frequent enough it even be correct, but that's still not understanding even 1 single word (or token) within either the question or the corpus.
An llm can, by understanding some features of the input, predict a categorisation of the input and feed it to do different processors. This already works. It doesn't require anything beyond the capabilities llms actually have, and isn't perfect. It's a very good question why this hasn't happened here; an llm can very reliably give you the answer to "how do you sum some data in python" so it only needs to be able to do that in excel and put the result into the cell.
There are still plenty of pitfalls. This should not be one of them, so that's interesting.