"Israel: what a cuntry"
Witty. I like it.
"Israel: what a cuntry"
Witty. I like it.
Well now I'm curious and don't trust myself to find the correct answer. Why do we have this naming scheme?
If possible I would avoid being anywhere densely populated in the Netherlands over New Years. The whole country loses their fucking minds, handing explosives to children as young as ten with the advice: "Go have fun in the street, kid". Strangers shoot fireworks in every direction, at buildings, into the canals, at random strangers just trying to get to shelter.
When I lived there, my girlfriend and I would always book a holiday well out of town on NYE. It's insane, and not in a fun way.
Have a look at this short video of some streets "before and after". Hidalgo (the mayor) has given Paris a complete makeover. People are swimming in the Siene again!
As a persistent Green supporter voting in his riding, I'd be hard pressed not to vote for him.
"My Time at Portia": it's not exactly the best-coded game ive ever played (weird geometry and animation bugs, and some of the plots feel half-assed) but the world is big, and complicated, and there's lots of crafting and relationships, and overall Good Vibes. I built a bus stop last night and married a nice girl who sells flowers. I recommend.
It's currently on sale on GOG for €3.
Here's the link to the actual article. I get that you're trying to do users a favour to bypass tracking at the original URL, but the Internet Archive is a Free service that shouldn't be abused for link cleaning as it costs a lot of money to store and serve all this stuff and it's meant as an "archive", not an ad-blocking proxy.
I'm posting this in part because currently clicking that link errors it with a "too many requests" error. Let's try to be a little kinder to the good guys, shall we?
If users wasnt a cleaner/safer/faster browsing experience, I recommend ditching Chrome for Firefox and getting the standard set of extensions: uBlock Origin, Privacy Badger, etc.
mainly due to the cost of fighting the summer's wildfires.
When people say "we can't afford to do X to combat global warming" what they're really saying is that "doing X will be expensive for me. Let everyone else pay for it."
Climate inaction is yet another case of socialising costs to benefit short-term profits for the few and we need to start talking about it like this.
Carney's new pipeline plan is a classic case. He's just racking up the cost of survival in the future so his rich friends can get richer right now. It's theft.
Do you know how common it is for Israelis to conflate criticism of Israel with racism while they commit war crimes?
Conflating Jews with the IDF is a horrible, one might even argue antisemitic thing to do. They're murderers and genociders and you shouldn't be so quick to throw your lot in with them.
They should all be in prison.
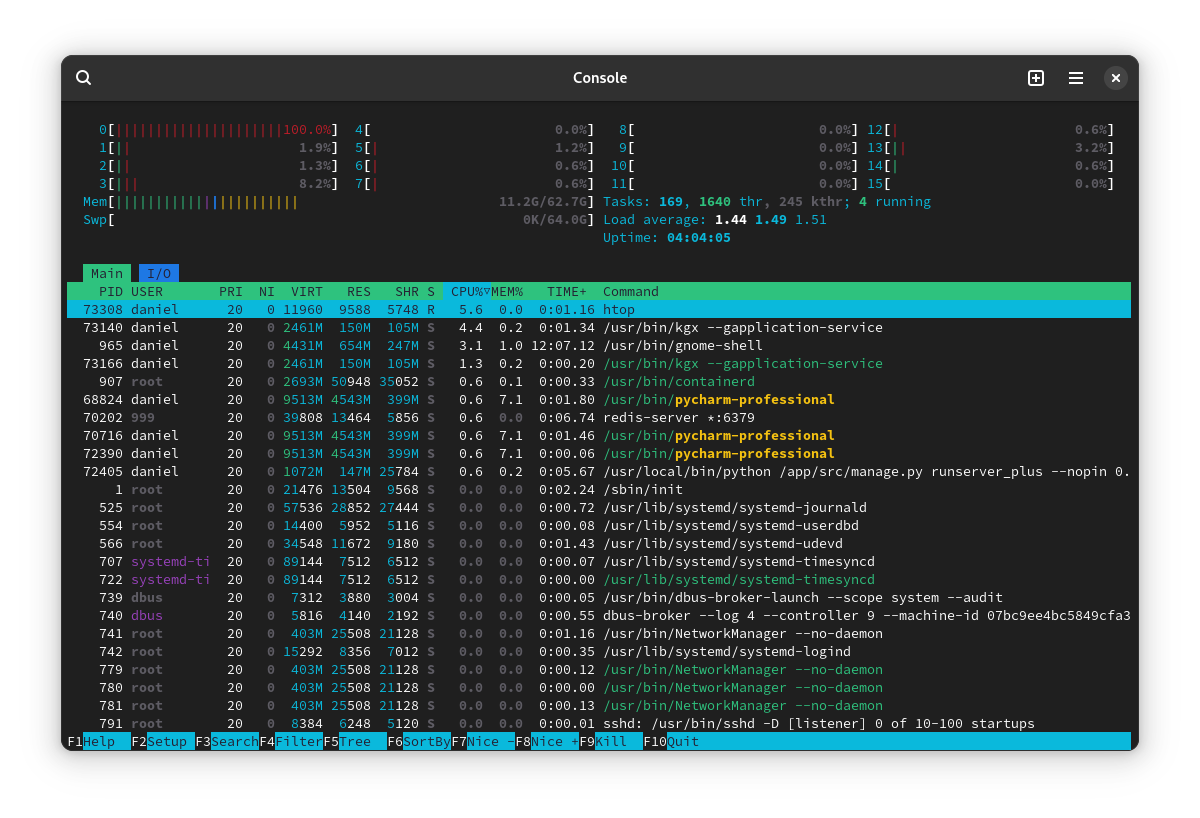
From time to time, often after I've restored from sleep or finished playing a Steam game, one of my CPU cores is pinned at 100% with no indication of what might be doing it. Running htop, btop, or GNOME system monitor all show the same thing: CPU0 at 100% while the rest are doing near-nothing, and no process in particular seems to be using those resources.
If I restart, it's back to normal, and sometimes I can play a game in Steam or let the computer go to sleep and it doesn't do this, but it happens often enough that's annoying/confusing so I'd like to know if there's a way to either (a) diagnose which processes are using which CPU cores, or (b) somehow "reset" the checking of these values to make sure that something's not just being misreported.
This is a desktop system running Arch & GNOME.
{kind=link}
But... "states' rights!"
I keep waiting for Republicans to revolt, but then I remember they're Republicans.