this post was submitted on 08 Feb 2026
1374 points (98.8% liked)
Fuck AI
5987 readers
1634 users here now
"We did it, Patrick! We made a technological breakthrough!"
A place for all those who loathe AI to discuss things, post articles, and ridicule the AI hype. Proud supporter of working people. And proud booer of SXSW 2024.
AI, in this case, refers to LLMs, GPT technology, and anything listed as "AI" meant to increase market valuations.
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
What about the AI that I run on my local GPU that is using a model trained on open source and public works?
It's cool as hell to train models don't get me wrong but if you use them as assistants you will still slowly stop thinking no?
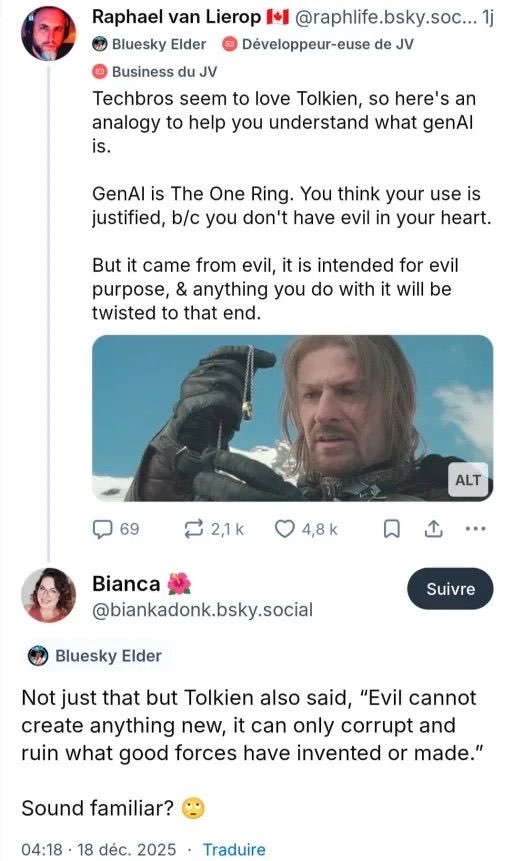
So Nazgûl.
Feels like telling me not to use a calculator so I don't forget how to add and subtract.
I've settled on a future model where AIs are familiars that level up from their experience more naturally and are less immediately omnipotent
Sounds like the rings of the Elves to me
This is very cool. Any advice a simple software engineer (me) could follow to practice the same?
Install LM Studio
Tell LM Studio to download the Apertus model: https://en.wikipedia.org/wiki/Apertus_(LLM)
Bob's ur uncle.
stick to 8B models for video cards with 8GB VRAM.
Thanks! I've always wanted an uncle bob, too!
your local model wouldn't exist without sauron (openai)
People were making LLMs before openai/chatgpt tbf.
It's the "destroy the environment and economy in an attempt to make something that sucks just enough to justify not paying people fairly so you can advertise to rich assholes gambling their generational wealth" that OpenAI invented for the LLMs.
what are those LLMs you mention that people are still using? never heard of them, sounds like a cop out
That is slightly less unethical than Claude or whatever, but it is still unethical.
Can you elaborate on why this is unethical?
I use 0.2kWh of electricity to spend a day coding with this model:
https://en.wikipedia.org/wiki/Apertus_(LLM)
It is still trained on open source code on GitHub. These code communities seemingly have no way to opt out of their free (libre) contributions being used as training data, nor does the resulting code generation contribute anything back to those communities. It is a form of license stripping. That's just one issue.
Just because your inference running locally doesn't use much electricity doesn't mean you've sidestepped all of the other ethical issues surrounding LLMs.
It is not trained on open source code on Github.
But I can use it to analyze a datasheet and generate a library for an obscure module that I can then upload to Github and contribute to the community.
Apertus is most certainly trained on source code hosted on GitHub. It is laid out here in their technical report:
https://github.com/swiss-ai/apertus-tech-report
It uses a large dataset called TheStack, among others.
That's not random Github accounts or "delicensing" anything. People had to opt IN to be part of "The Stack". Apertus isn't training itself from community code.
I'm tired of arguing with you about this, and you're still wrong. It was opt-out, not opt-in, based initially on a GitHub crawl of 137M repos and 52B files before filtering & dedup.
But again, you'd have to set your project to public and your license to "anyone can take my code and do whatever they want with it" before it'd be even added to that list. That's opt-in, not opt-out. I don't see the ethical dilemma here. I'm pretty sure I've found ethical AI, that produces good value for me and society, and I'm going to keep telling people about it and how to use it.